
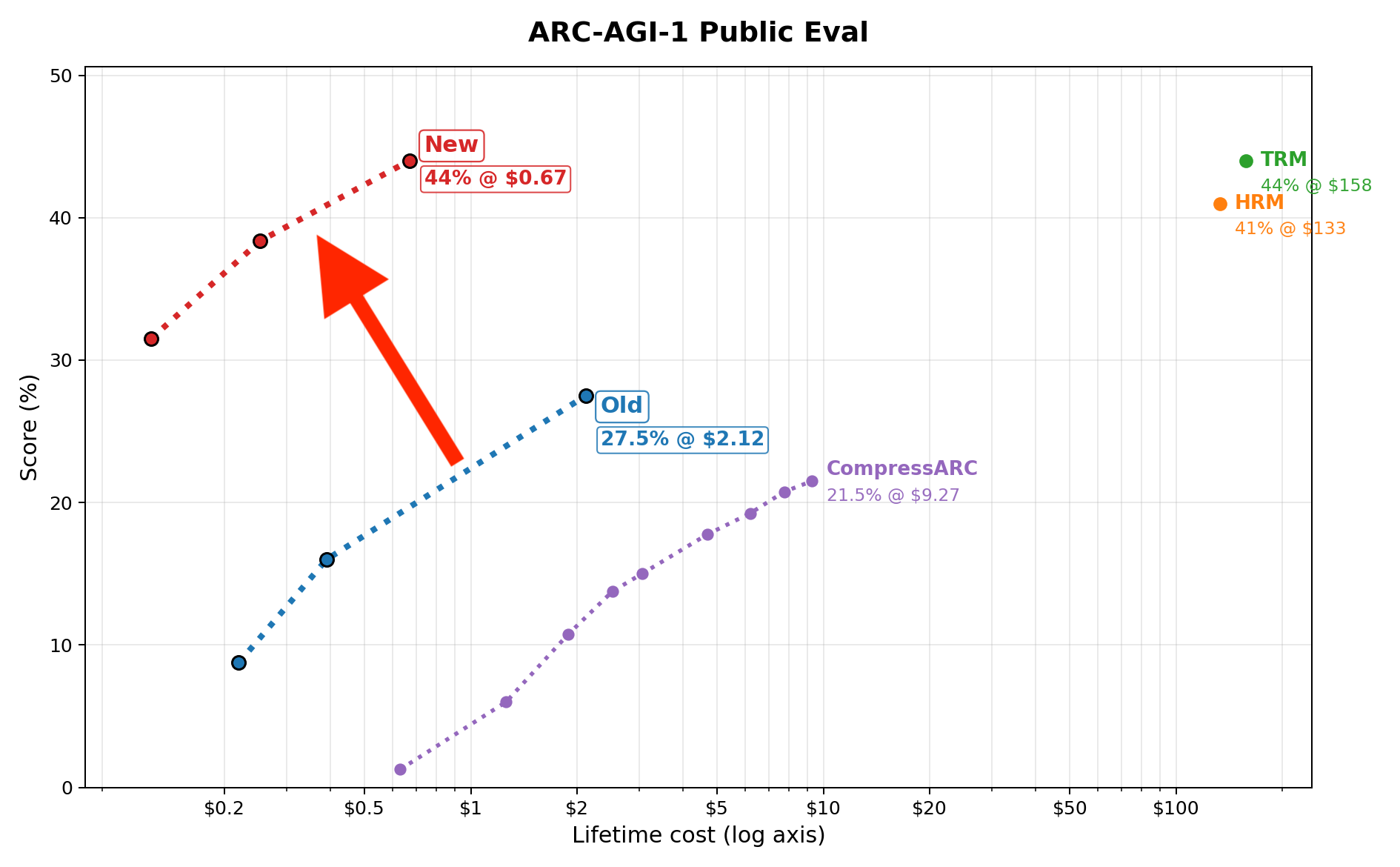
44% on ARC-AGI-1 in 67 cents
I trained a small transformer from scratch in 1.5hrs on a 5090
Beats many LLMs, and scores the same as TRM/HRM
This is an upgrade to my previous model
Faster, better, cheaper and still open source.
Also gets 7% on ARC-2
Discussion on Twitter, Code on github
This is the 3rd blog in a series of works on ARC-AGI. Prev: Blog 2, Blog 1.
Many ppl thought the prev result was impossible. It got attention from top researchers and went viral on X. Eg: Discussions by Lucas Beyer, Jeremy Howard, Rohan Anil, and comments by many others.
Why work on this?
I think sample efficiency is the most important problem in AI today and I want to solve it.
The intention behind this work is to (1) find the limits of sample efficiency when restricted to transformers / today’s deep learning methods and (2) reduce costs so iteration is much faster and cheaper.
ARC is a great benchmark to test this:
- Very few samples (only a 1000 puzzles) in a high dimensional space
- Its a metalearning benchmark, so each puzzle uses a different rule, with some common concepts
- Very few priors needed: every concept needed in the eval set is present in the train set
- It is incredibly easy for humans to solve, and accessible to even poor AI researchers
- Benchmark is still unsaturated (for data efficiency, ignore LLMs and approaches that use tons of synthetic data or human inductive biases)
Next, I’ll work on new research ideas to break these limits. I’ll try to keep costs low so that anyone in the world can work on this.
Tech details
How does it work?
The overall approach is similar to last time (full technical details here), but I added a bunch of upgrades. Here’s a quick summary of the approach:
- Each input-output pair is converted to a sequence of tokens. These sequences are autoregressively trained on by a small transformer. This is done from scratch at test time on both the train set and eval set puzzles (test labels hidden).
- To enable cross-task learning, each puzzle is given a separate additive embedding (learnt). Since each sequence has two 2D grids, positional are learnt using 3D RoPE embeddings.
- The sequences are augmented with color and dihedral permutations. During inference, the test inputs are augmented, and the inverse aug is applied on the outputs produced. The 2 most common outputs are submitted (AAIVR).
Changes since last time
The main goal was to find improvements to the architecture / algorithm that improve the sample efficiency of the model.
The biggest increases in scores were due to
- Modern architecture (SwiGlu instead of GELU, RMSnorm not layernorm, etc.)
- More data diversity, better shuffling of data
- scaling up: 8 layers instead of 4,
Biggest decreases in cost were due to:
- Way fewer augmentations (more sample efficient!)
- AdamW -> Normuon
- flash attention with varlen training + flex attention kernels for inference
A major change is that I don’t train on input tokens anymore. This means the loss function only includes output tokens (which makes the approach supervised). This. performs slightly better 40% $\to$ 44% but I don’t understand why. Perhaps finite model capacity
I also increased the training data by adding the non-overlapping tasks from ARC-2. I did this very carefully to ensure no leakage. You can remove the extra data if you don’t like it and it will still score ~40%, but it will need ~double the compute.
Context: ARC-2 contains 773 ARC-1 puzzles and 347 new puzzles. Most eval puzzles of ARC-1 are repeated, so if you naively train on ARC-2, then its a dataleak and you will score 100%. I avoid this by carefully filtering out the 773 repeated puzzles (so no leak!)
There are many other changes that gave incremental improvements in performance or speed. Find the full list of changes here.
Interesting behaviour
Since I am no longer training on inputs, this approach is now supervised. What’s weird is that the test loss is now worse, yet it scores better! Also it is more stable and there’s less variance in scores.
Many ppl today are working on sample efficiency by aiming for the lowest val loss on a small dataset. I think that’s great, but this points out a failure mode in such an approach
I do think the unsupervised style training will be better in some scenarios, and I am evaluating this.
Before NorMuon, I tried vanilla Muon. Obviously it trained much faster than AdamW, but the loss (and scores) would loiter at the end instead of converging. I found that cranking down the momentum and/or LR drastically at this point helped, but I didn’t want to make manually changes like this. When I switched to NorMuon, the problem disappeared
Ablations
The biggest contribution to performance seems to be good representations (3D RoPE + per-task embedding).
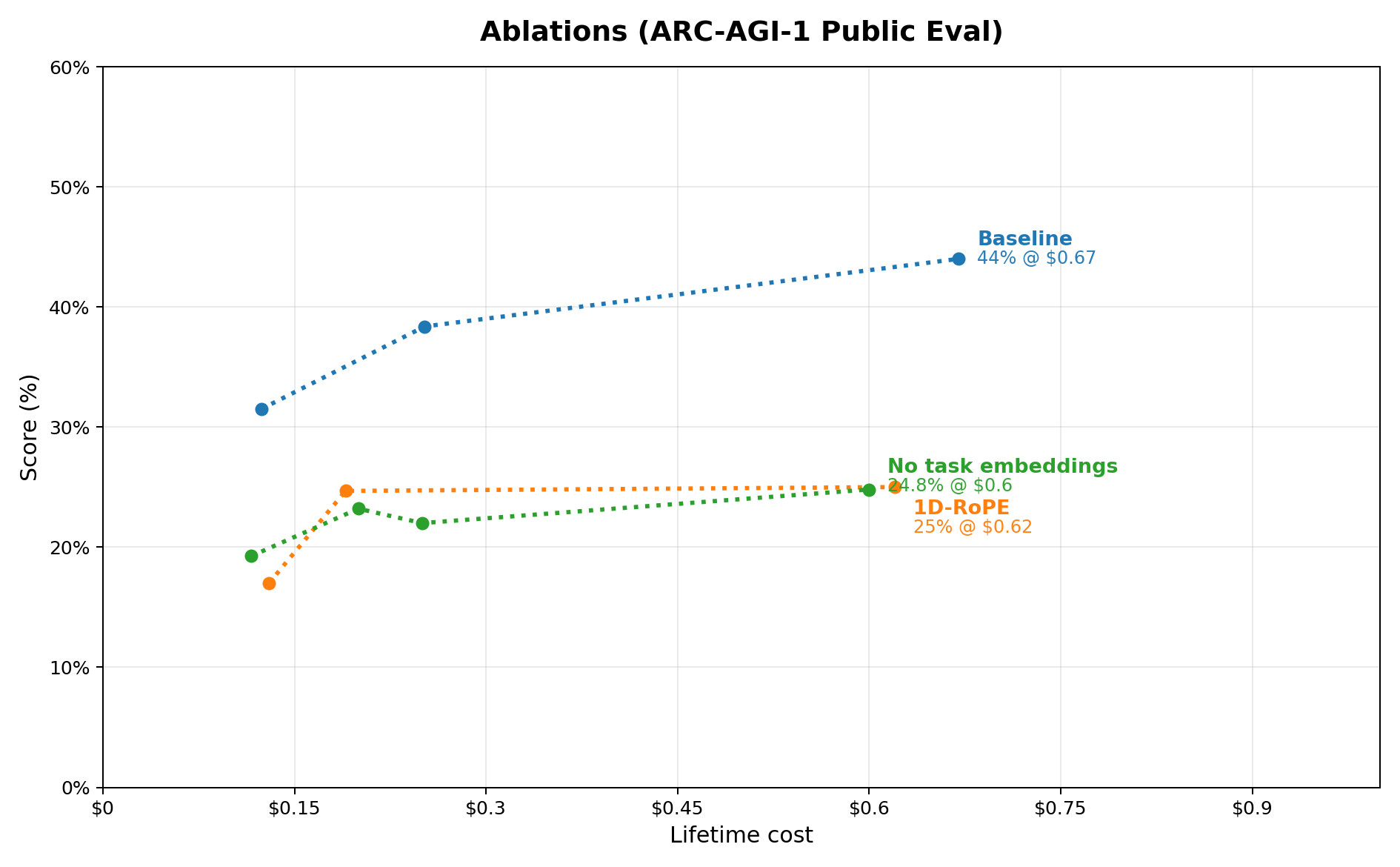
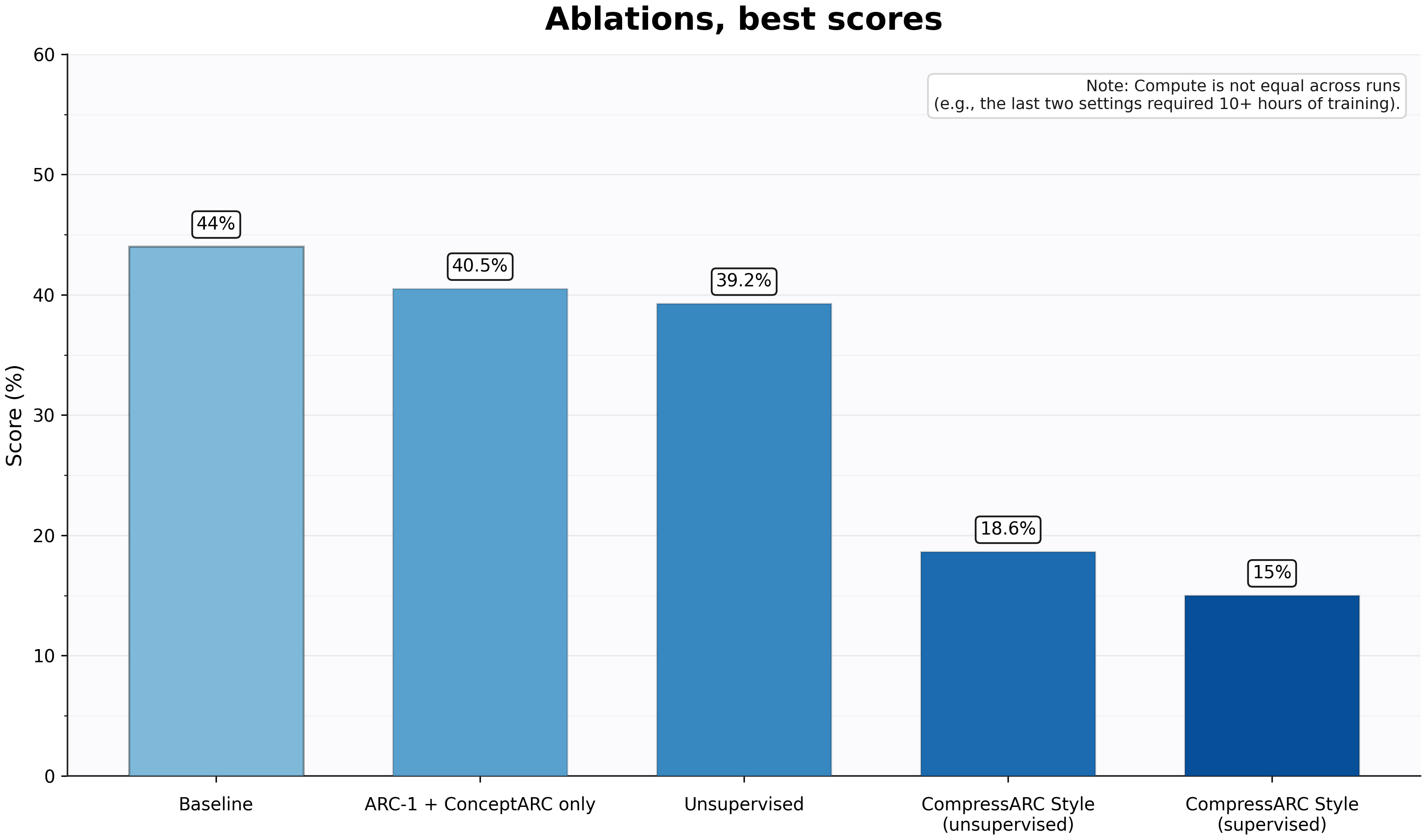
- Training on inputs performs slightly worse -> ~39%
- Restricting training set to ARC-1+ConceptARC only performs about the same: ~40%
- Switching from 3D RoPE to 1D drops score to ~24%
- Removing the per-task embeddings drops score to ~24%
- Running the model CompressARC style (training from scratch on each task separately, and unsupervised), gives a drops performance down to ~18%
- CompressARC but supervised gets ~15%
How can others contribute?
The code is open source. Feel free to modify it and improve score or reduce cost. (Pls don’t increase training data)
Try reaching 65% – you won’t need many modifications. Evidence: I took the union of all solved tasks from multiple runs, and got 55%. Also a bunch of other tasks are “almost” solved. Some ideas:
- RoPE mixes positional and content information, which probably worsens performance. PoPE should perform on par or better. Or maybe invent a new pos embedding
- The architecture can definitely be modernised further
Costs can probably be reduced 10x with handmade GPU code. There are architectural changes that can also do this.
Lastly, figure out how to remove data augmentations. (I hate that I used it, ignore everyone who thinks its okay). There are a few obvious ways to do so, but the challenge is keeping training costs low.
Misc
TBH, I didn’t expect to reach 45% with just the transformer, I thought this would need new ideas. I certainly didn’t expect to reach it at such low costs/flops. The ablations show that a surprising amount of perfomance is retained even without augmentations or synthetic data. Now I’m pretty sure 65% can be reached within the transformer framework
I don’t understand why others didn’t figure this out. Its just a transformer with the most obvious representation. This benchmark has been open for 6 years, was high profile, and had a million dollar prize! Maybe researchers underestimate deep learning? Maybe the cost of experimentation was high enough that they couldn’t run ablations properly? Blindsided by LLMs or using harnesses?
Appendix
Prev criticism/validation on my approach from famous researchers
My old result went viral on X and many experienced researchers debated about it, both for and against. Threads by Jeremy, Lucas, Susan, Andreas, Yoav, and many more. I’m listing all the criticisms here with my answers.
Training on the eval puzzles is cheating / “training on test”
- No this is false. “Training on test” specifically means training on the labels of test data. The labels were not trained on.
- Also, ARC is a metalearning benchmark, so you’re supposed to learn from the eval puzzles.
- Jargon: ARC has a set of train puzzles and a set of eval puzzles. Each puzzle has example pairs and test pairs. A pair consists of an input grid + output grid.
- The ARC, the label is only the test pair’s output grid in an eval puzzle.
- These labels were not trained on. They are hidden. You can delete it beforehand if you wish
Training on the inputs of eval puzzles leaks information
- No, this is false. Such an approach is called transductive reasoning and has been studied since the time of Vapnik.
- Also, this dogma of ignoring eval inputs doesn’t make sense in a world trying to solve continual learning
- Other approaches train a metalearning algorithm and then deploy it to learn by running a CoT or by modifying latents through a recurrent loo. My approach or what I did here is directly metalearn by modifying the weights of a single forward function is no different than learning by
- Note: in the new 44% result, training on inputs has been removed as it scores slightly worse
Even if training on eval puzzle inputs is allowed, the test input specifically should be forbidden
- No, this is false. The same “transduction” argument applies here
- A metalearning benchmark can be transductive in 2 ways:
- train puzzle $\to$ eval puzzles
- within the eval puzzle, example pair $\to$ test pair
- This criticism is specifically answered by the latter
This is against testing policy
- No this is false.
- The policy says “test taker must not know what the test will be”. People interpreted this as saying TTT is banned. But it actually refers to the human designing the AI system, not the AI system itself.
- Eg: to discourage designing inductive biases based on the eval set.
- To anyone active in the ARC community, this has always been clear since test time training has been allowed and encouraged. Steven and Chew’s comments clarify this and other concerns.
- TTT also follows the spirit of a metalearning benchmark, so its fine!
You are not including training costs
- No, this is false. I show the entire lifetime compute. This is the cost of training the model from init + the total cost of running inference on all tasks. Yes it totally amounts to 67 cents. Check the prices of a 5090 for 2hrs on vast.ai
Test time training is traditionally done one task at a time. Training on all test tasks at once is unrealistic
- Yes, this criticism makes sense. But it’s nuanced
- I agree that its rare to see to face problem sets in real life where every problem is given at once. Even if it is (like an exam), humans can usually only attempt one at a time
- But just because humans don’t have a capability shouldn’t mean it invalidates building an AI model with that capability. Otherwise we could say LLMs are unrealistic since humans can’t train on the entire internet / can’t read tokens as fast
- Also, it is unclear if humans are limited to one might be able to train on different data from multiple sensory at a time, exactly like
Providing cost per task amortises cost of training since all test tasks are trained on at once. So comparing other models is unfair
- Yeah this is fair. In my defense:
- That’s how the organisers compare every model, including TRM which also trains on all test tasks at once
- I was also more generous by including training and inference costs while LLMs and other models exclude pre-training/offline training costs.
- I have now switched to (a) showing lifetime compute cost instead of per-task, (b) comparing only with TRM, HRM and CompressARC and not with LLMs / other methods and (c) I added ablations with comparable training styles
Answering criticism about ARC-AGI itself
When I posted last time, there was a lot of debate about ARC-AGI itself. Some were valid, but a lot of them were questions Chollet has answered many times before:
- What does ARC even test for? (fluid intelligence)
- Why should we care about ARC? (fluid intelligence isn’t fully solved)
- Solving ARC-AGI will not lead to AGI (no one claimed that)
- ARC keeps shifting goalposts / its adversarially constructed for LLMs (Both are false)
Chollet’s paper and these tweets1 are good sources. Summing up his stance: The benchmark intended to test fluid intelligence, which he considers necessary but not sufficient for AGI. Solving ARC-1 / 2 implies non-zero fluid intelligence, but it isn’t an upper bound. The benchmarks don’t signal AGI is reached, they intend to point out the right research questions to ask. There were no goalposts moved: ARC-1 precedes LLMs, ARC-2 was announced pre-chatGPT and ARC-3 was announced before ARC-2 was saturated. He’s also happy about progress on ARC since it documents progress in AI.
I mainly care about ARC since it can be used to test for sample efficiency which is an important unsolved problem today! It’s also a well constructed meta-learning benchmark, and is accessible to GPU poor peeps. Historically, its been great at pointing out the strengths and flaws of LLMs. I also think its cool that the benchmark stood unsaturated for 6 years, despite being high profile / having a large cash prize since we now know DL can perform extraordinarily well on ARC-1/2.
There are some valid criticisms IMO:
- They should disallow synthetic data for ARC-1/2
- Its against the spirit of the benchmark and yet most top scores today rely on large amounts of it
- synthetic data lowers the bar of fluid intelligence needed to solve puzzles
- It only made sense till 2024 when DL scores sucked.
- We now know LLMs/DL can learn anything given enough training data
- This would also make the benchmark a great test for sample efficiency. It would complement ARC-3 very well
- Question is how to prevent synthetic data? Simple:
- Its against the spirit of the benchmark and yet most top scores today rely on large amounts of it
- Ban offline training/pretraining. Models must train from scratch after submission
- Previously this was considered impossible so rule. My model shows this is possible
- Guarantees no synthetic data can be used
- It makes the comparison fair across differet models. Otherwise some models like LLMs can benchmaxx ARC by using ungodly amounts of offline training. (Since the benchmark has been around a long time, many ARC-like datasets have been created)
- A single leaderboard graph comparing multiple types of models doesn’t make sense. It brings the following 3 problems (solution: separate charts)
- The x-axis is cost/task. But it only counts online compute cost. Some of these models (like LLMs) have massive offline pretraining phases whose costs arent counted. You can use infinite training compute to effectively bring the test set into distribution, so these models should be evaluated separately.
- Dividing cost by number of tasks makes no sense for the models that train on all test tasks at once (like mine, TRM & HRM)
- Comparing LLMs on the public eval set makes no sense since the answers to the public puzzles are available on the internet
- The organisers drew premature conclusions from TRM and HRM and attributed success to recursive loops+deep supervision. I think this bias is because they assume pure deep learning can’t solve ARC (eg: base LLMs still suck at ARC-2). I disagree
- The wording of the testing policy can be improved to remove confusion. (Explained here)
Mistakes that I think other approaches are making
Assuming recursion is the next big thing (Eg: HRM, TRM, Arcprize blog)
I do see the appeal, but there aren’t enough ablations to prove this. And my model shows you can reach the same performance without recursion. The only confirmed benefit of recursion is allowing you to increase compute without increasing memory movement.
Misleading advertising by HRM/TRM: I also don’t like that TRM advertised itself as a 7M model when there are O(100M+) embedding weights being trained. It is misleading, makes it more like a lookup table, and calls into question what causes the performance. Worst case it should have been called 7M “active” weights. Same for HRM. Both didn’t mention this anywhere!
LLM based approaches on ARC aren’t showing new capabilities anymore:
Watching LLMs climb the ARC leaderboard has been extremely useful as explained below, but I don’t think there’s much to learn from their ARC-1/ARC-2 scores anymore:
- Increases in LLM scores are now mainly driven by post training (evidence in next section) and are probably a function of amount of synthetic data. They are learning to solve ARC tasks, not learn general abstract reasoning
- There’s also too many confounding factors to glean anything from new scores. Comparing LLMs based on benchmarks is bad science in general (eg: differing amounts of training data aimed at a benchmark)
- For LLMs, only private scores should count. Their scores on the public leaderboard are useless as the answers are available on the internet, and are trained on.
- Using harnesses on top of LLMs to improve performance makes little sense to me. All the post-training magic is happening inside the frontier labs, and they can build harnesses themselves. I think its unlikely continual learning will be solved by a harness.
Anti-bitter lesson cheats
I have already argued before that synthetic data and augmentations are bad. Designing inductive biases into the model is also bad. The fact that we can’t scale this benchmark without cheating like this shows that there are still breakthroughs waiting. I hope more people try to reduce such tricks that are anti-bitter lesson.
Learnings from LLMs on ARC-AGI
LLMs have now saturated v1 and v2 of this benchmark. Here’s what I infer from their progress:
ARC-AGI predates LLMs. They performed terribly on the benchmarks initially, showing that pretraining doesn’t confer general reasoning capabilities and that LLMs can suck at tasks that are incredibly easy for humans
OpenAI’s O1 getting 75% was a big win for LLMs. It suggested that given enough data, LLMs can learn any task during post-training. I assume this is what Sholto Douglas often argues about.
When ARC-2 came out, it reset progress of all LLMs, including the thinking ones. This suggests even post-training doesn’t confer general reasoning capabilities, otherwise a model that performs well on ARC-1 would automatically perform well on ARC-2.
(Basically, the models are learning how to solve ARC puzzles, not general abstract reasoning and its scores on a task are dependent on how well it is represented in its training data. Also, I’m not sure whether “general reasoning” even exists in the first place? Maybe humans are specialised too)
Since then, thinking LLMs have made steady progress on ARC-2. People often think this means models are better at general reasoning BUT what they don’t notice is that the base models are stuck at single digits. Taken with other evidence, this suggests:
- Scores on ARC-2 are driven by post-training. (Probably largely depend on amount of synthetic ARC data?)
- Labs are benchmaxxing (probably coz customers care about benchmark performance?)
- LLMs are not sample efficient in any way.
Don’t get me wrong, I am very bullish on LLMs. The trends on ARC-2 show that performance will keep improving with increase in compute and data. Its also incredible to see the reduction in inference costs.
Full list of changes
Changes that modify training dynamics
- Optimizer changed from AdamW-only to NorMuon + auxiliary AdamW
- LR schedule changed from warmup+cosine to WSD schedule (warmup %, hold, then linear decay to floor).
LayerNormwas replaced byRMSNorm- FFN changed from
Linear -> GELU -> Linearto SwiGLU-style gated FFN (chunk + SiLU gate). - Weight decay changed from “non-attention linear only” to explicit group-wise decay: attention weights, token embeddings, and task/dihedral embeddings each have their own WD knobs.
- Training objective changed from
outputs["loss"](unsupervised style input+output LM loss) tooutputs["output_loss"](supervised style) only. - Training batching changed from smart bucketing based on length to true random batching (bucketing retained for inference paths).
- Straggler/incomplete batches are now dropped in training (
drop_last=Trueenforced). - Dataset construction now supports/uses broader sources (ARC-1, ARC-2, ConceptARC, optional filtered cross-dataset tasks, submission/private modes), changing train data composition.
- Color augmentation changed from one global epoch-level permutation to per-example augmentation tuples (color + dihedral).
- Color permutation domain changed to excludes output-only colors, instead of blind 1..9 permutations.
- Augmentation generation now deduplicates transformed inputs via hashing across a task (higher unique-sample diversity).
- Augmentation selection is now epoch-cycled with shuffled candidate order (without-replacement per cycle behavior)
- Changes in hyperparams: optimizer/hparams, epochs, augment cap/type, depth (
n_layers), and dataset path. - A new
dihedral_embeddingwas added and is now summed into token conditioning. (Only a very mild performance increase)
Speed increases without changing training dynamics:
- Training batches changed from padded
[B,S]to packed token stream withcu_seqlens(no pad tokens in train path). - Attention path changed from padded SDPA masking to packed varlen flash-attention support (
cu_seqlens), plus flex-attention decode kernels. - Dihedral augmentation moved from offline dataset expansion to online augmentation selection at collate time.
- Build-time training split changed from
("train","test")to("train",)
Misc.
- Resume behavior changed: optimizer-switch/hparam-change detection now can reset/rewarm schedule, altering resumed-run dynamics.
- Scheduler stepping changed to fractional epoch progress when training, instead of pure per-step cosine progression.
TODO: ADD CITATIONS
Chollet’s original paper about the ARC benchmark, some of his tweets explaining what it intends to test, and two tweets explaining the timeline of how the benchmark has evolved. ↩